31.12.2021
Soluție online pentru cele mai mici pătrate. Unde se folosește metoda celor mai mici pătrate?
Metodă cele mai mici pătrate(LSM) vă permite să estimați diferite cantități folosind rezultatele multor măsurători care conțin erori aleatorii.
Caracteristicile MNE
Ideea principală a acestei metode este că suma erorilor pătrate este considerată un criteriu pentru acuratețea rezolvării problemei, pe care se străduiesc să o minimizeze. Atunci când se utilizează această metodă, pot fi utilizate atât abordări numerice, cât și abordări analitice.
În special, ca implementare numerică, metoda celor mai mici pătrate implică luarea cât mai multor măsurători ale unei variabile aleatoare necunoscute. Mai mult, cu cât mai multe calcule, cu atât soluția va fi mai precisă. Pe baza acestui set de calcule (date inițiale) se obține un alt set de soluții estimate, din care apoi se selectează cea mai bună. Dacă se parametriză setul de soluții, atunci metoda celor mai mici pătrate se va reduce la găsirea valorii optime a parametrilor.
Ca abordare analitică a implementării LSM pe un set de date inițiale (măsurători) și un set așteptat de soluții, se determină una anume (funcțională), care poate fi exprimată printr-o formulă obținută ca o anumită ipoteză care necesită confirmare. În acest caz, metoda celor mai mici pătrate se reduce la găsirea minimului acestei funcționale pe setul de erori pătrate ale datelor originale.
Vă rugăm să rețineți că nu sunt erorile în sine, ci pătratele erorilor. De ce? Faptul este că adesea abateri ale măsurătorilor de la valoare exacta sunt atât pozitive, cât și negative. La determinarea mediei, suma simplă poate duce la o concluzie incorectă cu privire la calitatea estimării, deoarece anularea valorilor pozitive și negative va reduce puterea de eșantionare a măsurătorilor multiple. Și, în consecință, acuratețea evaluării.
Pentru a preveni acest lucru, se însumează abaterile la pătrat. Mai mult, pentru a egaliza dimensiunea valorii măsurate și estimarea finală, se extrage suma erorilor pătrate.
Unele aplicații MNC
MNC este utilizat pe scară largă în diverse domenii. De exemplu, în teoria probabilității și statistica matematică, metoda este utilizată pentru a determina o astfel de caracteristică a unei variabile aleatoare precum abaterea standard, care determină lățimea intervalului de valori ale variabilei aleatoare.
Este utilizat pe scară largă în econometrie sub forma unei interpretări economice clare a parametrilor săi.
Regresia liniară se reduce la găsirea unei ecuații de formă
sau
Ecuația formei permite pe baza valorilor parametrilor specificate X au valori teoretice ale caracteristicii rezultante, substituind valorile reale ale factorului în ea X.
Construcția regresiei liniare se reduce la estimarea parametrilor săi - AȘi V. Estimările parametrilor de regresie liniară pot fi găsite folosind diferite metode.
Abordarea clasică a estimării parametrilor de regresie liniară se bazează pe metoda celor mai mici pătrate(MNC).
Metoda celor mai mici pătrate ne permite să obținem astfel de estimări ale parametrilor AȘi V, la care suma abaterilor pătrate ale valorilor reale ale caracteristicii rezultante (y) din calculat (teoretic) minim:
Pentru a găsi minimul unei funcții, trebuie să calculați derivatele parțiale pentru fiecare dintre parametri AȘi bși setați-le egale cu zero.
Să notăm cu S, atunci:
Transformând formula, obținem următorul sistem de ecuații normale pentru estimarea parametrilor AȘi V:
Rezolvând sistemul de ecuații normale (3.5) fie prin metoda eliminării secvențiale a variabilelor, fie prin metoda determinanților, găsim estimările necesare ale parametrilor. AȘi V.
Parametru V numit coeficient de regresie. Valoarea acestuia arată modificarea medie a rezultatului cu o modificare a factorului cu o unitate.
Ecuația de regresie este întotdeauna completată cu un indicator al proximității conexiunii. Când se utilizează regresia liniară, un astfel de indicator este coeficientul de corelație liniară. Există diferite modificări ale formulei coeficientului de corelație liniară. Unele dintre ele sunt prezentate mai jos:
După cum se știe, coeficientul de corelație liniară este în limitele: -1 ≤ ≤ 1.
Pentru a evalua calitatea selecției unei funcții liniare, se calculează pătratul
Coeficient de corelație liniară numit coeficient de determinare. Coeficientul de determinare caracterizează proporția de varianță a caracteristicii rezultate y, explicată prin regresie, în varianța totală a trăsăturii rezultate:
În consecință, valoarea 1 caracterizează ponderea de varianță y, cauzate de influența altor factori neluați în considerare în model.
Întrebări pentru autocontrol
1. Esența metodei celor mai mici pătrate?
2. Câte variabile oferă regresia perechi?
3. Ce coeficient determină apropierea legăturii dintre modificări?
4. În ce limite se determină coeficientul de determinare?
5. Estimarea parametrului b în analiza corelației-regresiune?
1. Christopher Dougherty. Introducere în econometrie. - M.: INFRA - M, 2001 - 402 p.
2. S.A. Borodich. Econometrie. Minsk LLC „Noi cunoștințe” 2001.
3. R.U. Rakhmetova Curs scurt de econometrie. Tutorial. Almaty. 2004. -78p.
4. I.I. Eliseeva.Econometrie. - M.: „Finanțe și Statistică”, 2002
5. Revista lunară de informare și analitică.
Modele economice neliniare. Modele de regresie neliniară. Transformarea variabilelor.
Modele economice neliniare..
Transformarea variabilelor.
Coeficientul de elasticitate.
Dacă există relații neliniare între fenomenele economice, atunci acestea sunt exprimate folosind funcțiile neliniare corespunzătoare: de exemplu, o hiperbolă echilaterală , parabole de gradul doi etc.
Există două clase de regresii neliniare:
1. Regresii care sunt neliniare în raport cu variabilele explicative incluse în analiză, dar liniare în raport cu parametrii estimați, de exemplu:
Polinoame de diferite grade - , ;
Hiperbola echilaterală - ;
Funcția semilogaritmică - .
2. Regresii care sunt neliniare în parametrii estimați, de exemplu:
Putere -;
Demonstrativ - ;
Exponenţial - .
Suma totală a abaterilor pătrate ale valorilor individuale ale caracteristicii rezultate la din valoarea medie este cauzată de influența mai multor motive. Să împărțim condiționat întregul set de motive în două grupuri: factor studiat xȘi alti factori.
Dacă factorul nu influențează rezultatul, atunci linia de regresie de pe grafic este paralelă cu axa OhȘi
Atunci întreaga varianță a caracteristicii rezultate se datorează influenței altor factori și suma totală a abaterilor pătrate va coincide cu reziduul. Dacă alți factori nu influențează rezultatul, atunci y legat Cu X funcțional și suma reziduală a pătratelor este zero. În acest caz, suma abaterilor pătrate explicate prin regresie este aceeași cu suma totală a pătratelor.
Deoarece nu toate punctele câmpului de corelație se află pe linia de regresie, împrăștierea lor apare întotdeauna ca urmare a influenței factorului X, adică regresie la De X,și cauzate de alte cauze (variație inexplicabilă). Adecvarea unei linii de regresie pentru prognoză depinde de ce parte din variația totală a trăsăturii laține seama de variația explicată
Evident, dacă suma abaterilor pătrate datorate regresiei este mai mare decât suma reziduală a pătratelor, atunci ecuația de regresie este semnificativă statistic și factorul X are un impact semnificativ asupra rezultatului u.
, adică cu numărul de libertate de variație independentă a unei caracteristici. Numărul de grade de libertate este legat de numărul de unități ale populației n și de numărul de constante determinate din aceasta. În raport cu problema studiată, numărul de grade de libertate ar trebui să arate câte abateri independente de la P
Evaluarea semnificației ecuației de regresie în ansamblu este dată folosind F- Criteriul Fisher. În acest caz, se propune o ipoteză nulă că coeficientul de regresie este egal cu zero, adică. b = 0 și, prin urmare, factorul X nu afectează rezultatul u.
Calculul imediat al testului F este precedat de analiza varianței. Locația centrală ocupă descompunerea sumei totale a abaterilor pătrate ale variabilei la din valoarea medie laîn două părți - „explicat” și „neexplicat”:
Suma totală a abaterilor pătrate;
Suma abaterii pătrate explicată prin regresie;
Suma reziduală a abaterilor pătrate.
Orice sumă a abaterilor pătrate este legată de numărul de grade de libertate , adică cu numărul de libertate de variație independentă a unei caracteristici. Numărul de grade de libertate este raportat la numărul de unități de populație nşi cu numărul de constante determinate din acesta. În raport cu problema studiată, numărul de grade de libertate ar trebui să arate câte abateri independente de la P posibil necesar pentru a forma o sumă dată de pătrate.
Dispersia pe grad de libertateD.
Raporturi F (test F):
Dacă ipoteza nulă este adevărată, atunci factorul și variațiile reziduale nu diferă unul de celălalt. Pentru H 0, este necesară o respingere astfel încât dispersia factorului să depășească dispersia reziduală de câteva ori. Statisticianul englez Snedekor a elaborat tabele de valori critice F-relaţii la diferite niveluri de semnificaţie ale ipotezei nule şi diferite numere de grade de libertate. Valoarea tabelului F-criteriul este valoarea maximă a raportului de varianțe care poate apărea în cazul divergenței aleatoare pentru un nivel dat de probabilitate a prezenței ipotezei nule. Valoarea calculată F-relațiile sunt considerate de încredere dacă o este mai mare decât tabelul.
În acest caz, ipoteza nulă despre absența unei relații între semne este respinsă și se trage o concluzie despre semnificația acestei relații: F fapt > F tabel H 0 este respins.
Dacă valoarea este mai mică decât cea din tabel F fapt ‹, F tabel, atunci probabilitatea ipotezei nule este mai mare decât un nivel specificat și nu poate fi respinsă fără riscul serios de a trage o concluzie greșită despre prezența unei relații. În acest caz, ecuația de regresie este considerată nesemnificativă statistic. Dar el nu se abate.
Eroarea standard a coeficientului de regresie
Pentru a evalua semnificația coeficientului de regresie, valoarea acestuia este comparată cu eroarea sa standard, adică se determină valoarea reală t-Testul studentului: care este apoi comparat cu valoarea tabelului la un anumit nivel de semnificație și număr de grade de libertate ( n- 2).
Eroare de parametru standard A:
Semnificația coeficientului de corelație liniară este verificată pe baza mărimii erorii coeficient de corelație t r:
Varianta totală a trăsăturilor X:
Regresia liniară multiplă
Construirea modelului
Regresie multiplă reprezintă o regresie a unei caracteristici efective cu doi sau mai mulți factori, adică un model al formei
Regresia poate da rezultate bune în modelare dacă influența altor factori care afectează obiectul de studiu poate fi neglijată. Comportamentul variabilelor economice individuale nu poate fi controlat, adică nu este posibil să se asigure egalitatea tuturor celorlalte condiții pentru evaluarea influenței unui factor studiat. În acest caz, ar trebui să încercați să identificați influența altor factori introducându-i în model, adică să construiți o ecuație de regresie multiplă: y = a+b 1 x 1 +b 2 +…+b p x p + .
Scopul principal al regresiei multiple este de a construi un model cu un număr mare de factori, determinând în același timp influența fiecăruia dintre ei separat, precum și impactul lor combinat asupra indicatorului modelat. Specificația modelului include două game de aspecte: selecția factorilor și alegerea tipului de ecuație de regresie
Metoda celor mai mici pătrate utilizat pentru estimarea parametrilor ecuației de regresie.Una dintre metodele de studiu a relațiilor stocastice dintre caracteristici este analiza de regresie.
Analiza regresiei este derivarea unei ecuații de regresie, cu ajutorul căreia se găsește valoarea medie a unei variabile aleatoare (atribut rezultat) dacă se cunoaște valoarea altei (sau a altor) variabile (atribute-factor). Acesta include următorii pași:
- selectarea formei de conectare (tipul ecuației de regresie analitică);
- estimarea parametrilor ecuației;
- evaluarea calității ecuației de regresie analitică.
În cazul unei relații liniare pe perechi, ecuația de regresie va lua forma: y i =a+b·x i +u i . Parametrii a și b ai acestei ecuații sunt estimați din datele de observație statistică x și y. Rezultatul unei astfel de evaluări este ecuația: , unde , sunt estimări ale parametrilor a și b , este valoarea atributului (variabilă) rezultat obținut din ecuația de regresie (valoarea calculată).
Cel mai adesea folosit pentru estimarea parametrilor metoda celor mai mici pătrate (LSM).
Metoda celor mai mici pătrate oferă cele mai bune estimări (consistente, eficiente și nepărtinitoare) ale parametrilor ecuației de regresie. Dar numai dacă sunt îndeplinite anumite ipoteze privind termenul aleator (u) și variabila independentă (x) (vezi ipotezele MCO).
Problema estimării parametrilor unei ecuații de perechi liniare folosind metoda celor mai mici pătrate este după cum urmează: pentru a obține astfel de estimări ale parametrilor , , la care suma abaterilor pătrate a valorilor reale ale caracteristicii rezultante - y i din valorile calculate - este minimă.
Oficial criteriul OLS se poate scrie asa:  .
.
Metode de clasificare a celor mai mici pătrate
- Metoda celor mai mici pătrate.
- Metoda maximei probabilități (pentru un model de regresie liniară clasică normală, se postulează normalitatea reziduurilor de regresie).
- Metoda MOL a celor mai mici pătrate generalizate este utilizată în cazul autocorelării erorilor și în cazul heteroscedasticității.
- Metoda celor mai mici pătrate ponderate (un caz special de MCO cu reziduuri heteroscedastice).
Să ilustrăm ideea metoda clasica cele mai mici pătrate grafic. Pentru a face acest lucru, vom construi un grafic de împrăștiere pe baza datelor observaționale (x i, y i, i=1;n) într-un sistem de coordonate dreptunghiular (un astfel de diagramă de împrăștiere se numește câmp de corelație). Să încercăm să selectăm o linie dreaptă care este cea mai apropiată de punctele câmpului de corelație. Conform metodei celor mai mici pătrate, linia este selectată astfel încât suma pătratelor distanțelor verticale dintre punctele câmpului de corelație și această linie să fie minimă. 
Notație matematică pentru această problemă:  .
.
Valorile lui y i și x i =1...n ne sunt cunoscute; acestea sunt date observaționale. În funcția S ele reprezintă constante. Variabilele din această funcție sunt estimările necesare ale parametrilor - , . Pentru a găsi minimul unei funcții de două variabile, este necesar să se calculeze derivatele parțiale ale acestei funcții pentru fiecare dintre parametri și să le echivaleze cu zero, i.e. 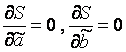 .
.
Ca rezultat, obținem un sistem de 2 ecuații liniare normale: 
Rezolvând acest sistem, găsim estimările parametrilor necesari: 
Corectitudinea calculului parametrilor ecuației de regresie poate fi verificată prin compararea sumelor (poate exista unele discrepanțe din cauza rotunjirii calculelor).
Pentru a calcula estimările parametrilor, puteți construi Tabelul 1.
Semnul coeficientului de regresie b indică direcția relației (dacă b >0, relația este directă, dacă b<0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
În mod formal, valoarea parametrului a este valoarea medie a lui y cu x egal cu zero. Dacă factorul-atribut nu are și nu poate avea o valoare zero, atunci interpretarea de mai sus a parametrului a nu are sens.
Evaluarea gradului de apropiere a relației dintre caracteristici
efectuată folosind coeficientul de corelație liniară pereche - r x,y. Poate fi calculat folosind formula:  . În plus, coeficientul de corelație liniară a perechii poate fi determinat prin coeficientul de regresie b:
. În plus, coeficientul de corelație liniară a perechii poate fi determinat prin coeficientul de regresie b:  .
.
Intervalul valorilor acceptabile ale coeficientului de corelație al perechii liniare este de la –1 la +1. Semnul coeficientului de corelație indică direcția relației. Dacă r x, y >0, atunci conexiunea este directă; dacă r x, y<0, то связь обратная.
Dacă acest coeficient este aproape de unitate în mărime, atunci relația dintre caracteristici poate fi interpretată ca una liniară destul de apropiată. Dacă modulul său este egal cu un ê r x , y ê =1, atunci relația dintre caracteristici este liniară funcțională. Dacă caracteristicile x și y sunt liniar independente, atunci r x,y este aproape de 0.
Pentru a calcula r x,y, puteți utiliza și Tabelul 1.
Pentru a evalua calitatea ecuației de regresie rezultată, calculați coeficientul teoretic de determinare - R 2 yx:  ,
,
unde d 2 este varianța lui y explicată prin ecuația de regresie;
e 2 - varianța reziduală (neexplicată prin ecuația de regresie) a lui y;
s 2 y - variația totală (totală) a lui y.
Coeficientul de determinare caracterizează proporția de variație (dispersie) a atributului rezultat y explicată prin regresie (și, în consecință, factorul x) în variația totală (dispersia) y. Coeficientul de determinare R 2 yx ia valori de la 0 la 1. În consecință, valoarea 1-R 2 yx caracterizează proporția de varianță y cauzată de influența altor factori neluați în considerare în erorile de model și de specificație.
Cu regresie liniară pereche, R 2 yx =r 2 yx.
Metoda celor mai mici pătrate obișnuite (OLS).- o metodă matematică utilizată pentru rezolvarea diverselor probleme, bazată pe minimizarea sumei abaterilor pătrate ale anumitor funcții de la variabilele dorite. Poate fi folosit pentru a „rezolva” sisteme de ecuații supradeterminate (când numărul de ecuații depășește numărul de necunoscute), pentru a găsi soluții în cazul sistemelor de ecuații neliniare obișnuite (nu supradeterminate), pentru a aproxima valorile punctuale ale unor funcţie. MCO este una dintre metodele de bază de analiză de regresie pentru estimarea parametrilor necunoscuți ai modelelor de regresie din datele eșantionului.
YouTube enciclopedic
1 / 5
✪ Metoda celor mai mici pătrate. Subiect
✪ Metoda celor mai mici pătrate, lecția 1/2. Funcție liniară
✪ Econometrie. Cursul 5. Metoda celor mai mici pătrate
✪ Mitin I.V. - Prelucrarea rezultatelor fizice. experiment - metoda celor mai mici pătrate (Lectura 4)
✪ Econometrie: Esența metodei celei mai mici pătrate #2
Subtitrări
Poveste
Până la începutul secolului al XIX-lea. oamenii de știință nu aveau anumite reguli pentru rezolvarea unui sistem de ecuații în care numărul de necunoscute este mai mic decât numărul de ecuații; Până atunci se foloseau tehnici private care depindeau de tipul de ecuații și de inteligența calculatoarelor și, prin urmare, calculatoare diferite, bazate pe aceleași date de observație, ajungeau la concluzii diferite. Gauss (1795) a fost primul care a folosit metoda, iar Legendre (1805) a descoperit-o și a publicat-o independent sub numele său modern (franceză. Méthode des moindres quarrés). Laplace a conectat metoda cu teoria probabilității, iar matematicianul american Adrain (1808) a luat în considerare aplicațiile sale teoretice probabilităților. Metoda a fost răspândită și îmbunătățită prin cercetări ulterioare ale lui Encke, Bessel, Hansen și alții.
Esența metodei celor mai mici pătrate
Lăsa x (\displaystyle x)- trusa n (\displaystyle n) variabile necunoscute (parametri), f i (x) (\displaystyle f_(i)(x)), , m > n (\displaystyle m>n)- un set de funcții din acest set de variabile. Sarcina este de a selecta astfel de valori x (\displaystyle x), astfel încât valorile acestor funcții să fie cât mai apropiate de anumite valori y i (\displaystyle y_(i)). În esență, vorbim despre „soluția” unui sistem de ecuații supradeterminat f i (x) = y i (\displaystyle f_(i)(x)=y_(i)), i = 1 , … , m (\displaystyle i=1,\ldots ,m)în sensul indicat de proximitate maximă a părților din stânga și din dreapta ale sistemului. Esența metodei celor mai mici pătrate este de a selecta ca „măsură de proximitate” suma abaterilor pătrate ale laturilor stângi și drepte. | f i (x) − y i | (\displaystyle |f_(i)(x)-y_(i)|). Astfel, esența MNC poate fi exprimată după cum urmează:
∑ i e i 2 = ∑ i (y i − f i (x)) 2 → min x (\displaystyle \sum _(i)e_(i)^(2)=\sum _(i)(y_(i)-f_( i)(x))^(2)\rightarrow \min _(x)).Dacă sistemul de ecuații are o soluție, atunci minimul sumei pătratelor va fi egal cu zero și soluțiile exacte ale sistemului de ecuații pot fi găsite analitic sau, de exemplu, folosind diverse metode de optimizare numerică. Dacă sistemul este supradeterminat, adică, în mod vag, numărul de ecuații independente mai multa cantitate variabilele dorite, atunci sistemul nu are o soluție exactă și metoda celor mai mici pătrate ne permite să găsim un vector „optim” x (\displaystyle x)în sensul proximităţii maxime a vectorilor y (\displaystyle y)Și f (x) (\displaystyle f(x)) sau proximitatea maximă a vectorului de abatere e (\displaystyle e) la zero (apropierea se înțelege în sensul distanței euclidiene).
Exemplu - sistem de ecuații liniare
În special, metoda celor mai mici pătrate poate fi folosită pentru a „rezolva” un sistem de ecuații liniare
A x = b (\displaystyle Ax=b),Unde A (\displaystyle A) matrice de dimensiuni dreptunghiulare m × n , m > n (\displaystyle m\times n,m>n)(adică numărul de rânduri ale matricei A este mai mare decât numărul de variabile căutate).
În cazul general, un astfel de sistem de ecuații nu are soluție. Prin urmare, acest sistem poate fi „rezolvat” doar în sensul alegerii unui astfel de vector x (\displaystyle x) pentru a minimiza „distanța” dintre vectori A x (\displaystyle Ax)Și b (\displaystyle b). Pentru a face acest lucru, puteți aplica criteriul minimizării sumei pătratelor diferențelor dintre laturile stânga și dreapta ale ecuațiilor sistemului, adică (A x - b) T (A x - b) → min x (\displaystyle (Ax-b)^(T)(Ax-b)\rightarrow \min _(x)). Este ușor de demonstrat că rezolvarea acestei probleme de minimizare duce la rezolvarea următorului sistem de ecuații
A T A x = A T b ⇒ x = (A T A) - 1 A T b (\displaystyle A^(T)Ax=A^(T)b\Rightarrow x=(A^(T)A)^(-1)A^ (T)b).MCO în analiza de regresie (aproximarea datelor)
Să fie n (\displaystyle n) valorile unor variabile y (\displaystyle y)(acestea ar putea fi rezultatele observațiilor, experimentelor etc.) și variabilelor aferente x (\displaystyle x). Provocarea este să ne asigurăm că relația dintre y (\displaystyle y)Și x (\displaystyle x) aproximativ cu o funcție cunoscută în cadrul unor parametri necunoscuți b (\displaystyle b), adică găsiți de fapt cele mai bune valori ale parametrilor b (\displaystyle b), aproximând la maxim valorile f (x, b) (\displaystyle f(x,b)) la valorile reale y (\displaystyle y). De fapt, acest lucru se reduce la cazul „rezolvării” unui sistem supradeterminat de ecuații cu privire la b (\displaystyle b):
F (x t , b) = y t , t = 1 , … , n (\displaystyle f(x_(t),b)=y_(t),t=1,\ldots,n).
În analiza de regresie și în special în econometrie, sunt utilizate modele probabilistice de dependență între variabile
Y t = f (x t , b) + ε t (\displaystyle y_(t)=f(x_(t),b)+\varepsilon _(t)),
Unde ε t (\displaystyle \varepsilon _(t))- așa-zisul erori aleatorii modele.
În consecință, abaterile valorilor observate y (\displaystyle y) de la model f (x, b) (\displaystyle f(x,b)) este deja presupus în modelul în sine. Esența metodei celor mai mici pătrate (obișnuită, clasică) este găsirea unor astfel de parametri b (\displaystyle b), la care suma abaterilor pătrate (erori, pentru modelele de regresie sunt adesea numite reziduuri de regresie) e t (\displaystyle e_(t)) va fi minim:
b ^ O L S = arg min b R S S (b) (\displaystyle (\hat (b))_(OLS)=\arg \min _(b)RSS (b)),Unde R S S (\displaystyle RSS)- Engleză Suma reziduală de pătrate este definită ca:
R S S (b) = e T e = ∑ t = 1 n e t 2 = ∑ t = 1 n (y t − f (x t , b)) 2 (\displaystyle RSS(b)=e^(T)e=\sum _ (t=1)^(n)e_(t)^(2)=\sum _(t=1)^(n)(y_(t)-f(x_(t),b))^(2) ).În cazul general, această problemă poate fi rezolvată prin metode de optimizare (minimizare) numerică. În acest caz ei vorbesc despre cele mai mici pătrate neliniare(NLS sau NLLS - engleză Non-Linear Least Squares). În multe cazuri este posibilă obținerea unei soluții analitice. Pentru a rezolva problema de minimizare, este necesar să se găsească puncte staționare ale funcției R S S (b) (\displaystyle RSS(b)), diferentiindu-l in functie de parametri necunoscuti b (\displaystyle b), echivalând derivatele cu zero și rezolvând sistemul de ecuații rezultat:
∑ t = 1 n (y t − f (x t , b)) ∂ f (x t , b) ∂ b = 0 (\displaystyle \sum _(t=1)^(n)(y_(t)-f(x_ (t),b))(\frac (\partial f(x_(t),b))(\partial b))=0).MCO în cazul regresiei liniare
Fie dependența de regresie liniară:
y t = ∑ j = 1 k b j x t j + ε = x t T b + ε t (\displaystyle y_(t)=\sum _(j=1)^(k)b_(j)x_(tj)+\varepsilon =x_( t)^(T)b+\varepsilon _(t)).Lăsa y este vectorul coloană de observații ale variabilei care se explică și X (\displaystyle X)- Acest (n × k) (\displaystyle ((n\time k)))-matricea observațiilor factorilor (rândurile matricei sunt vectori ai valorilor factorilor într-o observație dată, coloanele sunt un vector al valorilor unui anumit factor în toate observațiile). Reprezentarea matricială a modelului liniar are forma:
y = X b + ε (\displaystyle y=Xb+\varepsilon ).Atunci vectorul estimărilor variabilei explicate și vectorul reziduurilor de regresie vor fi egali
y ^ = X b , e = y - y ^ = y - X b (\displaystyle (\pălărie (y))=Xb,\quad e=y-(\pălărie (y))=y-Xb).În consecință, suma pătratelor reziduurilor de regresie va fi egală cu
R S S = e T e = (y - X b) T (y - X b) (\displaystyle RSS=e^(T)e=(y-Xb)^(T)(y-Xb)).Diferenţierea acestei funcţii în raport cu vectorul parametrilor b (\displaystyle b)și echivalând derivatele cu zero, obținem un sistem de ecuații (sub formă de matrice):
(X T X) b = X T y (\displaystyle (X^(T)X)b=X^(T)y).Sub formă de matrice descifrată, acest sistem de ecuații arată astfel:
(∑ x t 1 2 ∑ x t 1 x t 2 ∑ x t 1 x t 3 … ∑ x t 1 x t k ∑ x t 2 x t 1 ∑ x t 2 2 ∑ x t 2 x t 3 … ∑ x t 2 x t k ∑ x t 2 x t 1 ∑ x t 2 2 ∑ x t 2 x t 3 … ∑ x t 2 x t k ∑ x t 2 x t ∑ t ∑ t 2 x t 3 2 … ∑ x t 3 x t k ⋮ ⋮ ⋮ ⋱ ⋮ ∑ x t k x t 1 ∑ x t k x t 2 ∑ x t k x t 3 … ∑ x t k 2) (b 1 b 2 b 3 ⋮ y b 2 b 3 ⋮ y b x∑ t x∑ t x) x t 3 y t ⋮ ∑ x t k y t) , (\displaystyle (\begin(pmatrix)\sum x_(t1)^(2)&\sum x_(t1)x_(t2)&\sum x_(t1)x_(t3)&\ldots &\sum x_(t1)x_(tk)\\\sum x_(t2)x_(t1)&\sum x_(t2)^(2)&\sum x_(t2)x_(t3)&\ldots &\ suma x_(t2)x_(tk)\\\sum x_(t3)x_(t1)&\sum x_(t3)x_(t2)&\sum x_(t3)^(2)&\ldots &\sum x_ (t3)x_(tk)\\\vdots &\vdots &\vdots &\ddots &\vdots \\\sum x_(tk)x_(t1)&\sum x_(tk)x_(t2)&\sum x_ (tk)x_(t3)&\ldots &\sum x_(tk)^(2)\\\end(pmatrix))(\begin(pmatrix)b_(1)\\b_(2)\\b_(3) )\\\vdots \\b_(k)\\\end(pmatrix))=(\begin(pmatrix)\sum x_(t1)y_(t)\\\sum x_(t2)y_(t)\\ \sum x_(t3)y_(t)\\\vdots \\\sum x_(tk)y_(t)\\\end(pmatrix)),) unde toate sumele sunt preluate peste toate valorile valabile t (\displaystyle t).
Dacă o constantă este inclusă în model (ca de obicei), atunci x t 1 = 1 (\displaystyle x_(t1)=1)în fața tuturor t (\displaystyle t), prin urmare, în colțul din stânga sus al matricei sistemului de ecuații se află numărul de observații n (\displaystyle n), iar în elementele rămase din primul rând și prima coloană - pur și simplu sumele valorilor variabilelor: ∑ x t j (\displaystyle \sum x_(tj)) iar primul element din partea dreaptă a sistemului este ∑ y t (\displaystyle \sum y_(t)).
Rezolvarea acestui sistem de ecuații dă formula generala Estimări MCO pentru modelul liniar:
b ^ O L S = (X T X) - 1 X T y = (1 n X T X) - 1 1 n X T y = V x - 1 C x y (\displaystyle (\hat (b))_(OLS)=(X^(T) )X)^(-1)X^(T)y=\left((\frac (1)(n))X^(T)X\right)^(-1)(\frac (1)(n ))X^(T)y=V_(x)^(-1)C_(xy)).În scopuri analitice, ultima reprezentare a acestei formule se dovedește a fi utilă (în sistemul de ecuații la împărțirea la n, în loc de sume apar mediile aritmetice). Dacă într-un model de regresie datele centrat, atunci în această reprezentare prima matrice are semnificația unei matrice de covarianță eșantion de factori, iar a doua este un vector de covarianțe de factori cu variabila dependentă. Dacă în plus datele sunt de asemenea normalizat către MSE (adică, în cele din urmă standardizate), atunci prima matrice are semnificația unei matrice de corelație eșantion de factori, al doilea vector - un vector de corelații de eșantion de factori cu variabila dependentă.
O proprietate importantă a estimărilor MOL pentru modele cu constantă- linia regresiei construite trece prin centrul de greutate al datelor eșantionului, adică egalitatea este satisfăcută:
y ¯ = b 1 ^ + ∑ j = 2 k b ^ j x ¯ j (\displaystyle (\bar (y))=(\hat (b_(1)))+\sum _(j=2)^(k) (\hat (b))_(j)(\bar (x))_(j)).În special, în cazul extrem, când singurul regresor este o constantă, constatăm că estimarea MCO a singurului parametru (constanta însăși) este egală cu valoarea medie a variabilei explicate. Adică, media aritmetică, cunoscută pentru proprietățile sale bune din legile numerelor mari, este și o estimare a celor mai mici pătrate - satisface criteriul sumei minime a abaterilor pătrate de la aceasta.
Cele mai simple cazuri speciale
În cazul regresiei liniare perechi y t = a + b x t + ε t (\displaystyle y_(t)=a+bx_(t)+\varepsilon _(t)), când se estimează dependența liniară a unei variabile față de alta, formulele de calcul sunt simplificate (puteți face fără algebra matriceală). Sistemul de ecuații are forma:
(1 x ¯ x ¯ x 2 ¯) (a b) = (y ¯ x y ¯) (\displaystyle (\begin(pmatrix)1&(\bar (x))\\(\bar (x))&(\bar (x^(2)))\\\end(pmatrix))(\begin(pmatrix)a\\b\\\end(pmatrix))=(\begin(pmatrix)(\bar (y))\\ (\overline (xy))\\\end(pmatrix))).De aici este ușor să găsiți estimări ale coeficienților:
( b ^ = Cov (x , y) Var (x) = x y ¯ − x ¯ y ¯ x 2 ¯ − x ¯ 2 , a ^ = y ¯ − b x ¯ . (\displaystyle (\begin(cases)) (\hat (b))=(\frac (\mathop (\textrm (Cov)) (x,y))(\mathop (\textrm (Var)) (x)))=(\frac ((\overline) (xy))-(\bar (x))(\bar (y)))((\overline (x^(2)))-(\overline (x))^(2))),\\( \hat (a))=(\bar (y))-b(\bar (x)).\end(cases)))În ciuda faptului că în cazul general sunt de preferat modelele cu o constantă, în unele cazuri se știe din considerente teoretice că o constantă a (\displaystyle a) trebuie să fie egal cu zero. De exemplu, în fizică relația dintre tensiune și curent este U = I ⋅ R (\displaystyle U=I\cdot R); Când se măsoară tensiunea și curentul, este necesar să se estimeze rezistența. În acest caz, vorbim despre model y = b x (\displaystyle y=bx). În acest caz, în loc de un sistem de ecuații avem o singură ecuație
(∑ x t 2) b = ∑ x t y t (\displaystyle \left(\sum x_(t)^(2)\right)b=\sum x_(t)y_(t)).
Prin urmare, formula de estimare a coeficientului unic are forma
B ^ = ∑ t = 1 n x t y t ∑ t = 1 n x t 2 = x y ¯ x 2 ¯ (\displaystyle (\hat (b))=(\frac (\sum _(t=1)^(n)x_(t) )y_(t))(\sum _(t=1)^(n)x_(t)^(2)))=(\frac (\overline (xy))(\overline (x^(2)) ))).
Cazul unui model polinomial
Dacă datele sunt potrivite printr-o funcție de regresie polinomială a unei variabile f (x) = b 0 + ∑ i = 1 k b i x i (\displaystyle f(x)=b_(0)+\sum \limits _(i=1)^(k)b_(i)x^(i)), apoi, grade percepând x i (\displaystyle x^(i)) ca factori independenţi pentru fiecare i (\displaystyle i) este posibilă estimarea parametrilor modelului pe baza formulei generale de estimare a parametrilor unui model liniar. Pentru a face acest lucru, este suficient să ținem cont în formula generală că cu o astfel de interpretare x t i x t j = x t i x t j = x t i + j (\displaystyle x_(ti)x_(tj)=x_(t)^(i)x_(t)^(j)=x_(t)^(i+j))Și x t j y t = x t j y t (\displaystyle x_(tj)y_(t)=x_(t)^(j)y_(t)). În consecință, ecuațiile matriceale în acest caz vor lua forma:
(n ∑ n x t … ∑ n x t k ∑ n x t ∑ n x t 2 … ∑ n x t k + 1 ⋮ ⋮ ⋱ ⋮ ∑ n x t k ∑ n x t k + 1 … ∑ n x t 2 k) [ b 0 y∑ t ∑ t ∑ n∑ t ∑ t y t ⋮ ∑ n x t k y t ] . (\displaystyle (\begin(pmatrix)n&\sum\limits _(n)x_(t)&\ldots &\sum\limits _(n)x_(t)^(k)\\\sum \limits _( n)x_(t)&\sum \limits _(n)x_(t)^(2)&\ldots &\sum \limits _(n)x_(t)^(k+1)\\\vdots & \vdots &\ddots &\vdots \\\sum \limits _(n)x_(t)^(k)&\sum \limits _(n)x_(t)^(k+1)&\ldots &\ suma \limits _(n)x_(t)^(2k)\end(pmatrix))(\begin(bmatrix)b_(0)\\b_(1)\\\vdots \\b_(k)\end( bmatrix))=(\begin(bmatrix)\sum \limits _(n)y_(t)\\\sum \limits _(n)x_(t)y_(t)\\\vdots \\\sum \limits _(n)x_(t)^(k)y_(t)\end(bmatrix)).)
Proprietățile statistice ale estimatorilor MCO
În primul rând, observăm că pentru modelele liniare, estimările MCO sunt estimări liniare, după cum rezultă din formula de mai sus. Pentru estimări OLS nepărtinitoare, este necesar și suficient să se efectueze cea mai importantă condiție analiza de regresie: condiționată de factori, așteptarea matematică a unei erori aleatoare trebuie să fie egală cu zero. Această condiție, în special, este satisfăcută dacă
- așteptarea matematică a erorilor aleatoare este zero și
- factorii și erorile aleatoare sunt variabile aleatoare independente.
A doua condiție - condiția de exogeneitate a factorilor - este fundamentală. Dacă această proprietate nu este îndeplinită, atunci putem presupune că aproape orice estimări vor fi extrem de nesatisfăcătoare: nici măcar nu vor fi consecvente (adică chiar și o cantitate foarte mare de date nu ne permite să obținem estimări de înaltă calitate în acest caz ). În cazul clasic, se face o presupunere mai puternică despre determinismul factorilor, spre deosebire de o eroare aleatorie, ceea ce înseamnă automat că este îndeplinită condiția de exogeneitate. În cazul general, pentru consistența estimărilor, este suficientă satisfacerea condiției de exogeneitate împreună cu convergența matricei. V x (\displaystyle V_(x)) la o matrice nesingulară pe măsură ce dimensiunea eșantionului crește la infinit.
Pentru ca, pe lângă consecvență și imparțialitate, estimările celor mai mici pătrate (obișnuite) să fie și eficiente (cele mai bune din clasa estimărilor liniare imparțiale), trebuie îndeplinite proprietăți suplimentare ale erorii aleatoare:
Aceste ipoteze pot fi formulate pentru matricea de covarianță a vectorului de eroare aleatorie V (ε) = σ 2 eu (\displaystyle V(\varepsilon)=\sigma ^(2)I).
Un model liniar care satisface aceste condiții se numește clasic. Estimările MCO pentru regresia liniară clasică sunt estimări imparțiale, consistente și cele mai eficiente din clasa tuturor estimărilor nepărtinitoare liniare (în literatura engleză abrevierea este uneori folosită ALBASTRU (Cel mai bun estimator liniar imparțial) - cea mai bună estimare liniară imparțială; În literatura rusă este mai des citată teorema Gauss-Markov). După cum este ușor de arătat, matricea de covarianță a vectorului estimărilor de coeficienți va fi egală cu:
V (b ^ O L S) = σ 2 (X T X) - 1 (\displaystyle V((\hat (b))_(OLS))=\sigma ^(2)(X^(T)X)^(-1 )).
Eficiența înseamnă că această matrice de covarianță este „minimă” (orice combinație liniară de coeficienți, și în special coeficienții înșiși, au o varianță minimă), adică, în clasa estimatorilor liniari imparțiali, estimatorii MCO sunt cei mai buni. Elementele diagonale ale acestei matrice - varianțele estimărilor coeficienților - sunt parametri importanți ai calității estimărilor obținute. Cu toate acestea, nu este posibil să se calculeze matricea de covarianță deoarece varianța erorii aleatoare este necunoscută. Se poate dovedi că o estimare imparțială și consecventă (pentru un model liniar clasic) a varianței erorilor aleatoare este mărimea:
S 2 = R S S / (n - k) (\displaystyle s^(2)=RSS/(n-k)).
Înlocuind această valoare în formula pentru matricea de covarianță, obținem o estimare a matricei de covarianță. Estimările rezultate sunt, de asemenea, imparțial și consecvente. De asemenea, este important ca estimarea varianței erorii (și, prin urmare, a variației coeficienților) și estimările parametrilor modelului să fie independente variabile aleatoare, care vă permite să obțineți statistici de testare pentru a testa ipoteze despre coeficienții modelului.
Trebuie remarcat faptul că, dacă ipotezele clasice nu sunt îndeplinite, estimările parametrilor MCO nu sunt cele mai eficiente și, acolo unde W (\displaystyle W) este o matrice de greutate definită pozitivă simetrică. Cele mai mici pătrate obișnuite sunt un caz special această abordare, când matricea de ponderi este proporțională cu matricea de identitate. După cum se știe, pentru matrice (sau operatori) simetrice există o expansiune W = P T P (\displaystyle W=P^(T)P). Prin urmare, funcționalitatea specificată poate fi reprezentată după cum urmează e T P T P e = (P e) T P e = e ∗ T e ∗ (\displaystyle e^(T)P^(T)Pe=(Pe)^(T)Pe=e_(*)^(T)e_( *)), adică acest funcțional poate fi reprezentat ca suma pătratelor unor „rămăși” transformate. Astfel, putem distinge o clasă de metode ale celor mai mici pătrate - metodele LS (Least Squares).
S-a dovedit (teorema lui Aitken) că pentru un model de regresie liniară generalizată (în care nu sunt impuse restricții asupra matricei de covarianță a erorilor aleatoare), cele mai eficiente (din clasa estimărilor liniare nepărtinitoare) sunt așa-numitele estimări. Cele mai mici pătrate generalizate (GLS - Generalized Least Squares)- Metoda LS cu o matrice de ponderi egală cu matricea de covarianță inversă a erorilor aleatoare: W = V ε - 1 (\displaystyle W=V_(\varepsilon )^(-1)).
Se poate demonstra că formula pentru estimările GLS ale parametrilor unui model liniar are forma
B ^ G L S = (X T V - 1 X) - 1 X T V - 1 y (\displaystyle (\hat (b))_(GLS)=(X^(T)V^(-1)X)^(-1) X^(T)V^(-1)y).
Matricea de covarianță a acestor estimări va fi în consecință egală cu
V (b ^ G L S) = (X T V - 1 X) - 1 (\displaystyle V((\hat (b))_(GLS))=(X^(T)V^(-1)X)^(- 1)).
De fapt, esența MOL constă într-o anumită transformare (liniară) (P) a datelor originale și aplicarea MCO obișnuită la datele transformate. Scopul acestei transformări este ca pentru datele transformate, erorile aleatoare să satisfacă deja ipotezele clasice.
MCO ponderate
În cazul unei matrice de ponderi diagonale (și, prin urmare, a unei matrice de covarianță a erorilor aleatoare), avem așa-numitele Least Squares (WLS) ponderate. În acest caz, suma ponderată a pătratelor reziduurilor modelului este minimizată, adică fiecare observație primește o „pondere” care este invers proporțională cu varianța erorii aleatoare din această observație: e T W mi = ∑ t = 1 n e t 2 σ t 2 (\displaystyle e^(T)We=\sum _(t=1)^(n)(\frac (e_(t)^(2))(\ sigma_(t)^(2)))). De fapt, datele sunt transformate prin ponderarea observațiilor (împărțirea la o sumă proporțională cu abaterea standard estimată a erorilor aleatoare), iar datelor ponderate se aplică MCO obișnuite.
ISBN 978-5-7749-0473-0 .
Aproximarea datelor experimentale este o metodă bazată pe înlocuirea datelor obținute experimental cu o funcție analitică care trece cel mai aproape sau coincide în punctele nodale cu valorile originale (date obținute în timpul unui experiment sau experiment). În prezent, există două moduri de a defini o funcție analitică:
Prin construirea unui polinom de interpolare de n grade care trece direct prin toate punctele o matrice de date dată. În acest caz, funcția de aproximare este prezentată sub forma: un polinom de interpolare în formă Lagrange sau un polinom de interpolare în formă Newton.
Construind un polinom de aproximare de n grade care trece în imediata apropiere a punctelor dintr-o matrice de date dată. Astfel, funcția de aproximare netezește toate zgomotele aleatorii (sau erorile) care pot apărea în timpul experimentului: valorile măsurate în timpul experimentului depind de factori aleatori care fluctuează în funcție de propriile lor. legi aleatorii(erori de măsurare sau de instrument, inexactitate sau erori experimentale). În acest caz, funcția de aproximare este determinată folosind metoda celor mai mici pătrate.
Metoda celor mai mici pătrate(în literatura engleză Ordinary Least Squares, MCO) este o metodă matematică bazată pe determinarea unei funcții de aproximare care este construită în cea mai apropiată apropiere de puncte dintr-o serie dată de date experimentale. Apropierea funcțiilor originale și de aproximare F(x) este determinată de o măsură numerică și anume: suma abaterilor pătrate ale datelor experimentale de la curba de aproximare F(x) ar trebui să fie cea mai mică.
Curba de aproximare construită folosind metoda celor mai mici pătrate
Se folosește metoda celor mai mici pătrate:
Să rezolve sisteme de ecuații supradeterminate când numărul de ecuații depășește numărul de necunoscute;
Pentru a găsi o soluție în cazul sistemelor de ecuații neliniare obișnuite (nu supradeterminate);
Pentru a aproxima valorile punctuale cu o funcție de aproximare.
Funcția de aproximare folosind metoda celor mai mici pătrate este determinată din condiția sumei minime a abaterilor pătrate ale funcției de aproximare calculată dintr-o serie dată de date experimentale. Acest criteriu al metodei celor mai mici pătrate se scrie ca următoarea expresie:

Valorile funcției de aproximare calculate la punctele nodale,
O serie dată de date experimentale în puncte nodale.
Criteriul pătratic are o serie de proprietăți „bune”, cum ar fi diferențiabilitatea, oferind o soluție unică la problema de aproximare cu funcții de aproximare polinomială.
În funcție de condițiile problemei, funcția de aproximare este un polinom de gradul m
Gradul funcției de aproximare nu depinde de numărul de puncte nodale, dar dimensiunea acesteia trebuie să fie întotdeauna mai mică decât dimensiunea (numărul de puncte) unui tablou de date experimentale dat.
![]()
∙ Dacă gradul funcției de aproximare este m=1, atunci aproximăm funcția tabulară cu o dreaptă (regresie liniară).
∙ Dacă gradul funcției de aproximare este m=2, atunci aproximăm funcția tabelă cu o parabolă pătratică (aproximare pătratică).
∙ Dacă gradul funcției de aproximare este m=3, atunci aproximăm funcția tabelă cu o parabolă cubică (aproximație cubică).
În cazul general, când este necesar să se construiască un polinom aproximativ de gradul m pentru dat valorile tabelului, condiția pentru suma minimă a abaterilor pătrate asupra tuturor punctelor nodale este rescrisă în următoarea formă:
![]() - coeficienți necunoscuți ai polinomului de aproximare de gradul m;
- coeficienți necunoscuți ai polinomului de aproximare de gradul m;
Numărul de valori din tabel specificat.
O condiție necesară pentru existența unui minim al unei funcții este egalitatea cu zero a derivatelor sale parțiale în raport cu variabilele necunoscute. ![]() . Ca rezultat, obținem următorul sistem de ecuații:
. Ca rezultat, obținem următorul sistem de ecuații:

Să transformăm sistemul liniar de ecuații rezultat: deschideți parantezele și mutați termenii liberi în partea dreaptă a expresiei. Ca urmare, sistemul rezultat de expresii algebrice liniare va fi scris în următoarea formă:

Acest sistem de expresii algebrice liniare poate fi rescris sub formă de matrice:

Ca urmare, s-a obţinut un sistem de ecuaţii liniare de dimensiunea m+1, care constă din m+1 necunoscute. Acest sistem poate fi rezolvat folosind orice metodă de rezolvare a ecuațiilor algebrice liniare (de exemplu, metoda Gauss). Ca rezultat al soluției, se vor găsi parametri necunoscuți ai funcției de aproximare care furnizează suma minimă a abaterilor pătrate ale funcției de aproximare de la datele originale, adică. cea mai bună aproximare pătratică posibilă. Trebuie amintit că, dacă chiar și o valoare a datelor sursă se modifică, toți coeficienții își vor schimba valorile, deoarece sunt complet determinați de datele sursă.
Aproximarea datelor sursă prin dependență liniară
(regresie liniara)
Ca exemplu, luați în considerare tehnica de determinare a funcției de aproximare, care este dată în formă dependență liniară. În conformitate cu metoda celor mai mici pătrate, condiția pentru minimul sumei abaterilor pătrate este scrisă în următoarea formă:
Coordonatele nodurilor de tabel;
Coeficienți necunoscuți ai funcției de aproximare, care este specificat ca o dependență liniară.
O condiție necesară pentru existența unui minim al unei funcții este egalitatea la zero a derivatelor sale parțiale în raport cu variabilele necunoscute. Ca rezultat, obținem următorul sistem de ecuații:

Să transformăm sistemul liniar de ecuații rezultat.

Rezolvăm sistemul rezultat de ecuații liniare. Coeficienții funcției de aproximare în formă analitică se determină după cum urmează (metoda lui Cramer):

Acești coeficienți asigură construirea unei funcții liniare de aproximare în conformitate cu criteriul minimizării sumei pătratelor funcției de aproximare din valorile tabelare date (date experimentale).
Algoritm pentru implementarea metodei celor mai mici pătrate
1. Date inițiale:
Este specificată o serie de date experimentale cu numărul de măsurători N
Se precizează gradul polinomului de aproximare (m).
2. Algoritm de calcul:
2.1. Coeficienții sunt determinați pentru construirea unui sistem de ecuații cu dimensiuni

Coeficienții sistemului de ecuații ( partea stanga ecuații)
![]()
![]() - indicele numărului coloanei matricei pătrate a sistemului de ecuații
- indicele numărului coloanei matricei pătrate a sistemului de ecuații

Termeni liberi ai sistemului de ecuații liniare ( partea dreaptă ecuații)
![]() - indicele numărului de rând al matricei pătrate a sistemului de ecuații
- indicele numărului de rând al matricei pătrate a sistemului de ecuații
2.2. Formarea unui sistem de ecuații liniare cu dimensiunea .

2.3. Rezolvarea unui sistem de ecuații liniare pentru a determina coeficienții necunoscuți ai unui polinom de aproximare de gradul m.
2.4 Determinarea sumei abaterilor pătrate ale polinomului de aproximare de la valorile originale la toate punctele nodale

Valoarea găsită a sumei abaterilor pătrate este minimul posibil.
Aproximare folosind alte funcții
Trebuie remarcat faptul că atunci când se aproximează datele originale în conformitate cu metoda celor mai mici pătrate, funcția logaritmică, funcția exponențială și funcția de putere sunt uneori folosite ca funcție de aproximare.
Aproximație logaritmică
Să luăm în considerare cazul în care funcția de aproximare este dată de o funcție logaritmică de forma:

